
Image to Text OCR using Python

OCR stands for Optical Character Recognition which means recognition of written/ printed characters by the computer.
OCR enable to convert hard, non editable text embedded in different mediums such as PDF, images, scanned documents into editable digital text format which can be saved and edited digitally on a computer.
There are various open-source tools like Tesseract, GOCR, Ocrad which convert images into text.
Each tool has different algorithm to recognise and extract text from the source.
For example:
Ocrad OCR used feature extraction method whereas the Tesseract OCR uses the latest Artificial Intelligent LSTM Neural Network to extract characters from an image.
Tesseract OCR
Tesseract was originally developed at Hewlett-Packard Laboratories Bristol and at Hewlett-Packard Co, Greeley Colorado between 1985 and 1994, with some more changes made in 1996 to port to Windows, and some C++izing in 1998. In 2005 Tesseract was open sourced by HP. Since 2006 it is developed by Google.
Tesseract has 2 major versions
- Legacy Version 3.0
- LSTM version 4.1
Both are open source and can be explored and used by downloading it from its Github repository. [Tesseract OCR]
Using Tesseract
Since Tesseract OCW is an stand alone program it can be downloaded and used right after the installation by running the tesseract commands in command line or terminal.
You can also use the tesseract engine in your python script by using the Python-Tesseract Wrapper library.
Installing Tesseract.
- Install Tesseract installer [Tesseract Intaller]
- Verify the installation by running the command in command prompt or terminal.
tesseract --version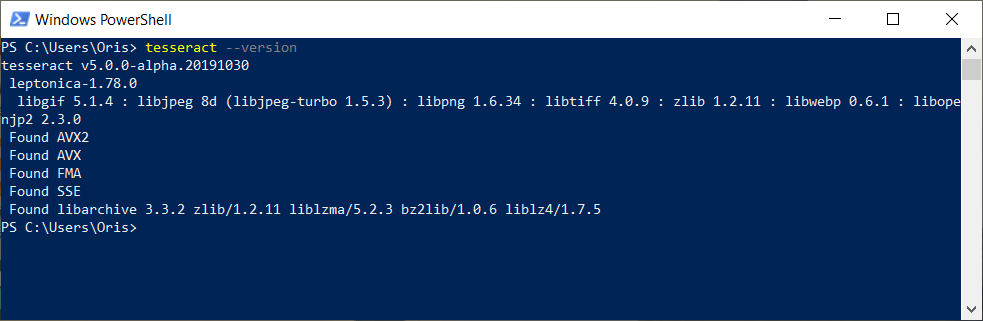

Converting Image to text with Tesseract OCR
- Open Command Prompt
- use “cd” command to navigate to the the folder where your image is saved.
- Alternatively you can use full path of image.
- Run command :
tesseract imagename.jpg out.txtThe above command takes the image file and feeds it to thee tesseract engine and saves the output in out.txt file.
Example of Tesseract OCR.
Sample Image:

Output File:
Output Text:
CASH RECEIPT
Shop Name
Address: Lorem Ipsum 3/18
Tel: 0987 123 890 5678
Date: MM/DD/YYYY
Manager: Lorem Ipsum
Lorem 2.15
Ipsum 8.75
Dolor sit 3.50
14.40
Using Tesseract For different languages:
You can use tesseract to recognize other languages by using the -l parameter and defining the language code explicitly.
tesseract receipt.jpg out -l eng+deuConvert Images Text into Searchable PDF using Tesseract:
tesseract receipt.jpg out pdfTesseract Engine Mode
Tesseract offers 4 engine mode based :
- 0 = Original Tesseract only.
- 1 = Neural nets LSTM only.
- 2 = Tesseract + LSTM.
- 3 = Default, based on what is available.
You can set the mode by using the –oem parameter in the command
tesseract receipt.jpg out --oem 1 Using Tesseract OCR engine in Python Image to Text conversion
To use Tesseract OCR engine in your python script you require the python-tesseract wrapper library
Install the pytesseract library Using the PIP:
pip install pytesseractIn python : imgae_to_string function of pytesseract library is used to conver Image into text. The function takes path of image as argument and returns the text in the image which can be saved in a variable or can be saved as text file.
print(pytesseract.image_to_string(Image.open('test.png')))For more Info: PyTesseract Wrapper
Sources:


